From our Wiki:
Both Jesse and Michael will work on finishing up the project and deployment. We will make sure that our work is fully compatible with the system we are working with and work out any last issues.
Deliverable: screenshots of the test curriculum and our role in it.
The goal of this deliverable was to wrap up and use it as a buffer to fix any issues that arose to make sure that what we had fully integrated into the system that our client had. We accomplished this by sending our work to him ahead of time to get his feedback. He was willing to help us by testing some of the functionality to make sure it was up to his expectations. As he did this and found a couple bugs or a miscommunication on an expectation, we fixed it. One example of this was the ability to update visualizations. What we had before was putting the visualizations on a separate location because of how long the runtime took. We thought it was best to leave the original visualizations and not overwrite them in case our client needed to interact with the data before the visualizations could finish. What we found out was that he instead wanted the visualizations updated on the same location which we were able to do by adjusting the code. This clarity and feedback is what this deliverable and additional time was for, fixing up issues that we had not foreseen. Since our client tested the system we gave him, he was completely satisfied with our results and made it the conclusion of our project.
Both Michael (10) and Jesse (10) worked equally on this deliverable.
Both Michael (10) and Jesse (10) worked equally on this deliverable.
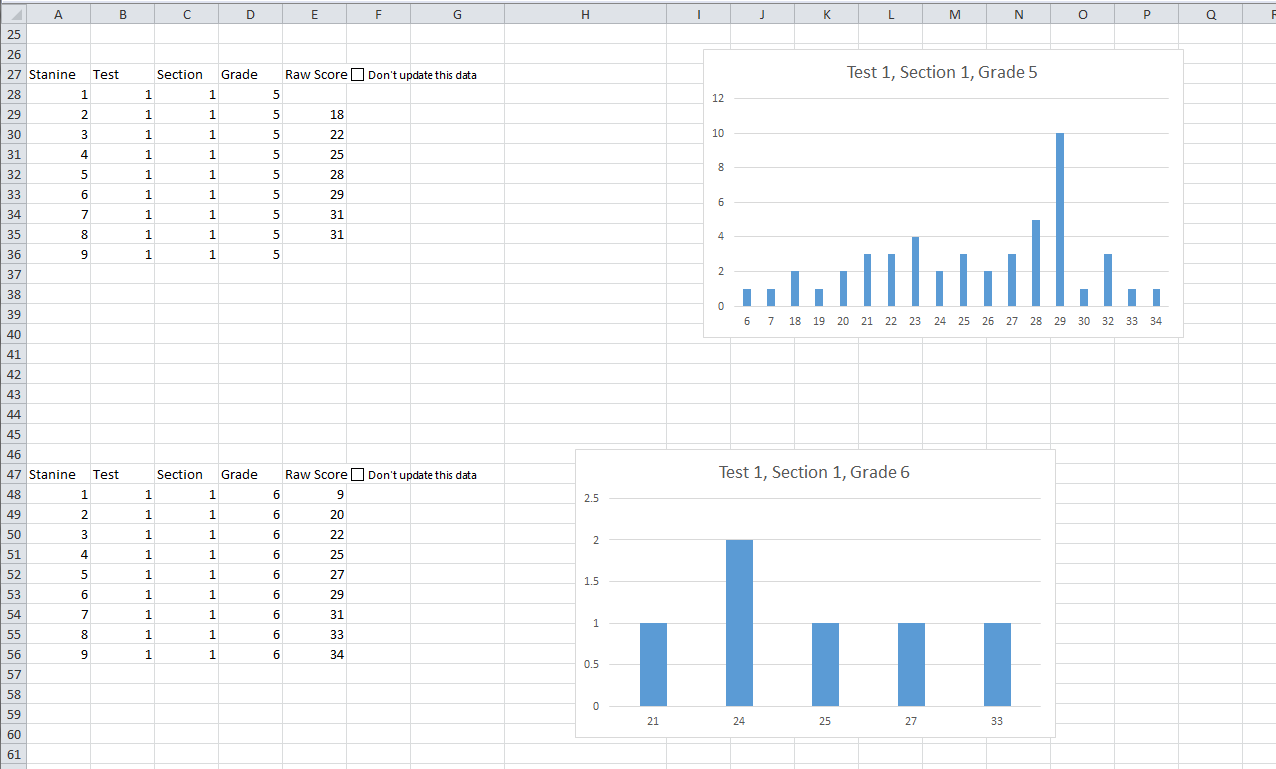
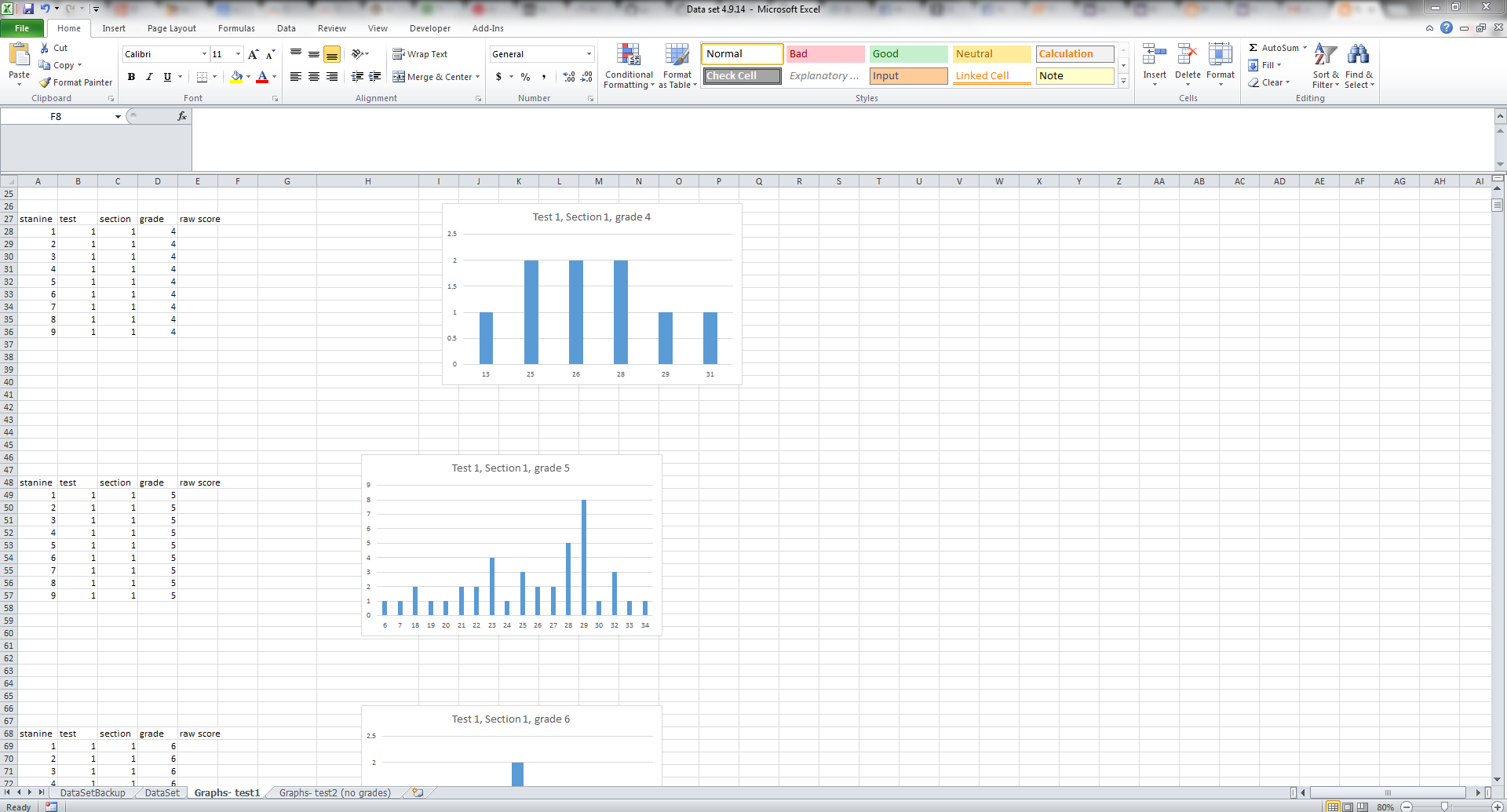
These next five images show what the site looks like. This is the dashboard we contributed to where the user sees their stanine scores, percentage in each section, and their raw score. There is a variety of other information for the user to browse through as well.